The Assured Trust Stack
Extending the Trust Stack across three classes of AI agent — with Internal Audit as the trust authority, and a Big Four variant for organisations that need external assurance
The Solo Trust Stack assumed you owned every agent. Most enterprises don't. By early 2026 the AI actually in use inside a mid-to-large organisation runs in three very different places: the agents you build, the agents embedded inside your SaaS vendors, and the agents your people invoke directly from their browsers. A trust layer that only covers the first covers a shrinking share of the problem. This piece describes what the Trust Stack looks like when it has to stretch across all three, and names the body that sits at the top: Internal Audit in the primary design, an external Big Four attestor in the alternative.
1 — The premise
In the original Trust Stack the picture was simple. An organisation deployed AI, the AI acted through a gateway, the gateway issued Trust Tokens. The Solo Trust Stack kept the same picture and just moved the validators inside one company. Both drafts implicitly assumed you were the one deciding what agent to deploy, what code it ran, and what systems it could reach. Two years into the enterprise AI cycle that assumption is no longer what most CIOs wake up to. The agents that matter most to their risk profile are no longer the ones they procured, and in many cases no longer the ones they know about.
The useful move is to stop treating “AI agent” as a single category and admit that three quite different things now share the label. Each takes a different shape of control, and a trust architecture that treats them as one category will either over-promise control it cannot deliver on two of them or under-invest in the ones it can.
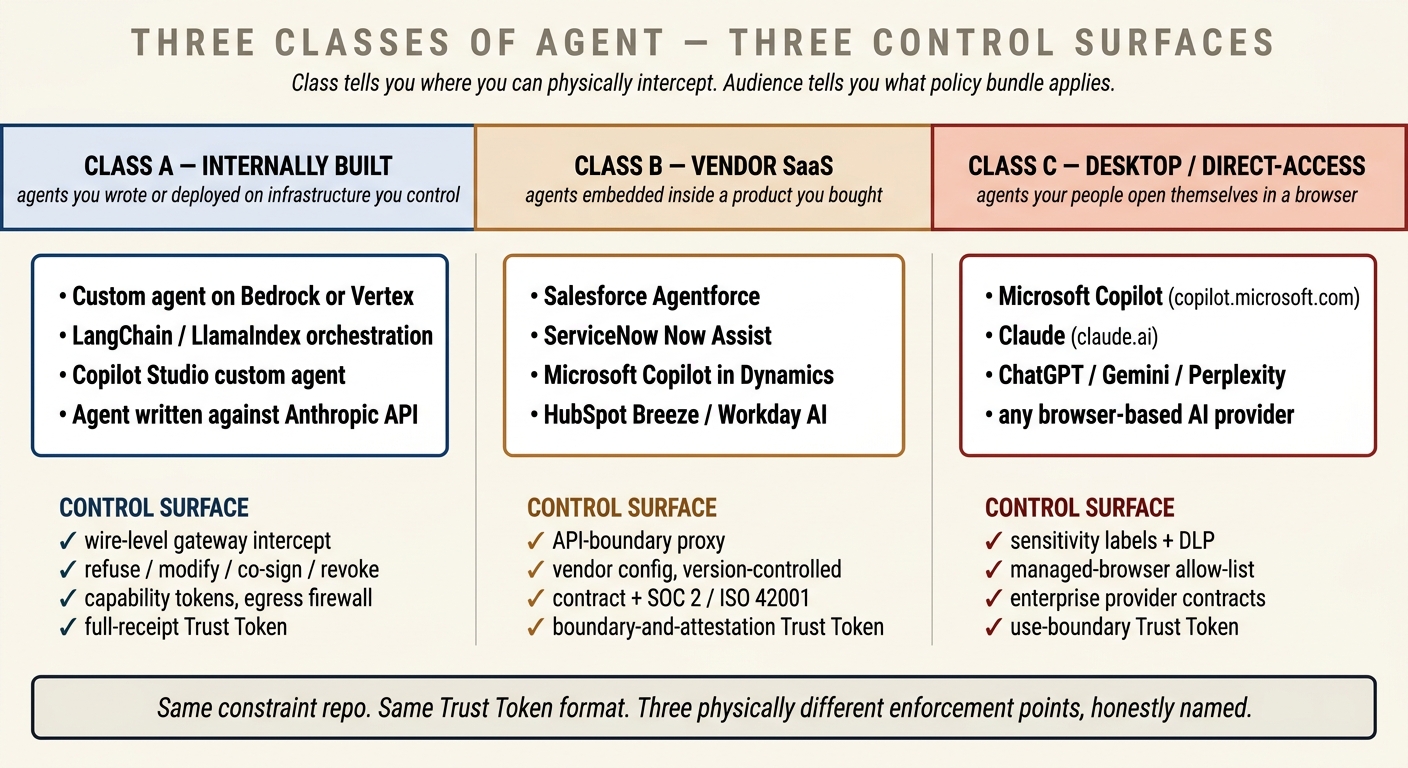
Class A — Internally built agents. Agents whose code, prompts, and tool-surfaces your own engineers control. A Python service on Bedrock or Vertex, a LangChain or LlamaIndex orchestration, a Copilot Studio custom agent shipped by your platform team, a claim-triage bot written against the Anthropic API. You can route every tool call through a gateway, mint credentials you revoke, enforce pre-flight policy, and keep the full Solo Trust Stack substrate in play. This is the world where the Trust Stack works as originally drafted.
Class B — Vendor SaaS agents. Agents shipped as part of a product you buy. Salesforce Agentforce, ServiceNow Now Assist, Microsoft Copilot inside Dynamics 365, HubSpot Breeze, Workday AI, your HRIS's embedded copilot, your observability vendor's incident agent. You chose the vendor, but the reasoning loop is theirs. You can shape what data the agent sees, which accounts it acts as, which webhooks it may reach, and — if you negotiated it — which audit feeds it emits. You cannot put yourself between the agent and the model. Control is exercised at the boundary, not at the wire, and a big share of your assurance comes through the vendor's own SOC 2 / ISO 42001 / AI-specific attestations and your contract with them.
Class C — Direct-access desktop agents. Microsoft Copilot at copilot.microsoft.com, Claude at claude.ai, ChatGPT, Gemini, Perplexity, and the coming flood of browser and native agents any employee can invoke with a credit card and a URL. Your people paste work into them, read the output, paste back. The model runs in a datacentre you have no presence in, on traffic you may not even see, and your employee has already conveyed whatever context went into the prompt. The Trust Stack's classic control points — gateway, capability tokens, egress policy — are not available. What is available sits in the data plane and on the endpoint: sensitivity labels on the documents the model could read, DLP on what the employee pastes in, managed-browser policy on which agents are reachable at all, and endpoint telemetry on the rest.
An architecture that tries to run all three classes through the same gateway will fail in two opposite ways: it will over-promise control for Class B and Class C (where the gateway cannot sit in the path) and under-invest in the things that actually work for them (contracts, attestations, data-plane controls, managed browsers). The Assured Trust Stack is the version of the picture where the three classes are named, their control surfaces are honest, and the trust authority reasons about each on its own terms.
2 — Why a trust authority
The Solo Trust Stack argued that three internal reporting lines — Risk and Compliance, Internal Audit, and AI Engineering — could stand in for three independent validator classes and co-sign the work. That framing still holds. What the three-class world changes is where the weight sits. When most of your AI is Class A, the engineering function does most of the work, and the other two functions audit it. When a non-trivial share is Class B and Class C, the engineering function can no longer physically enforce everything that matters, and the assurance and audit function has to carry more of the load. The stack needs a single body at the top whose mandate is broad enough to reason across all three classes, whose independence from the delivery org is structural, and whose sign-off means something beyond a ticket closing.
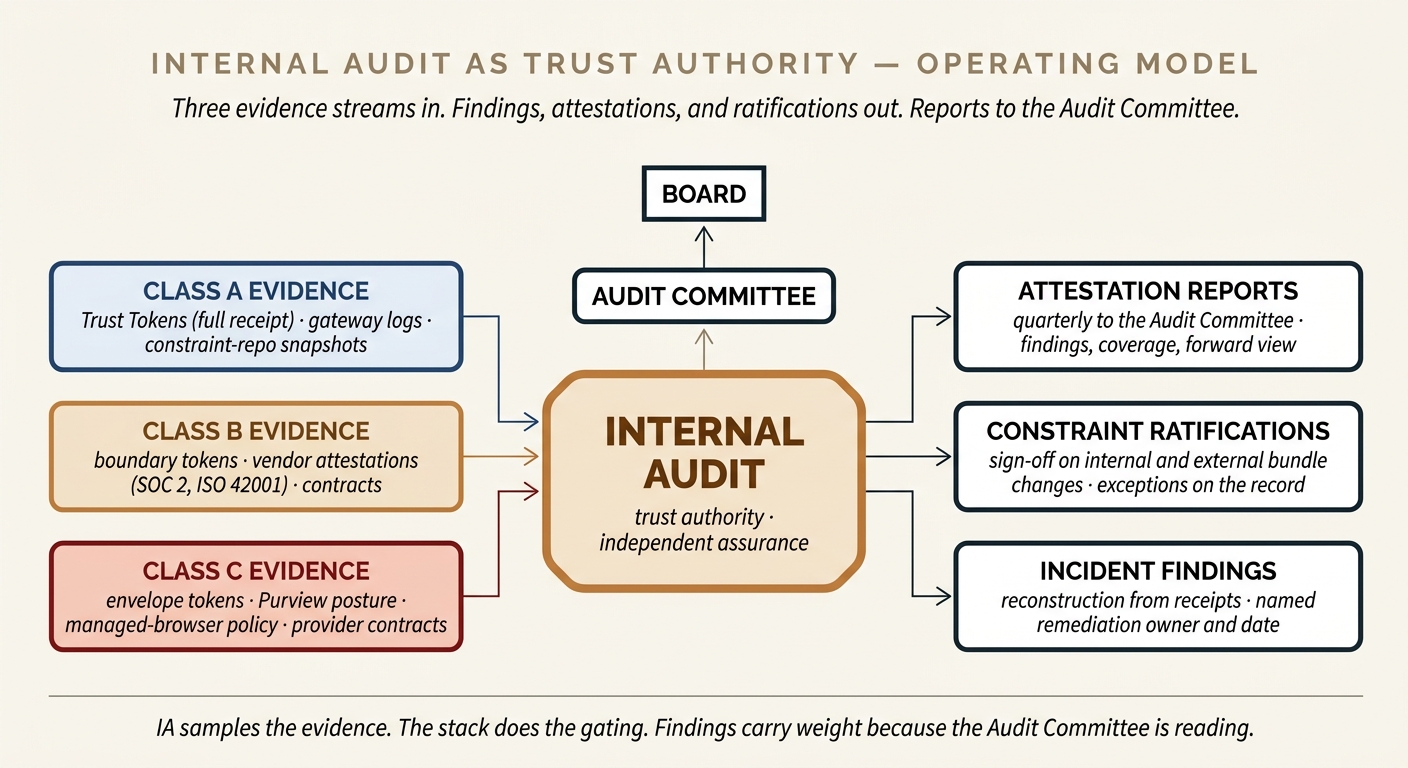
The obvious candidate for that body inside a regulated enterprise is the one that already exists and already has the mandate: Internal Audit. Not because they are the fastest or the most technical — they are usually neither — but because the three-lines-of-defence model that the business already runs on places them exactly where this function needs to sit. First line owns the work. Second line owns the risk framework. Third line — Internal Audit — provides independent assurance to the Audit Committee that the first two lines are doing what they claim. An AI trust authority that sits in the third line inherits standing, reporting lines, and a body (the Audit Committee) that can act on findings.
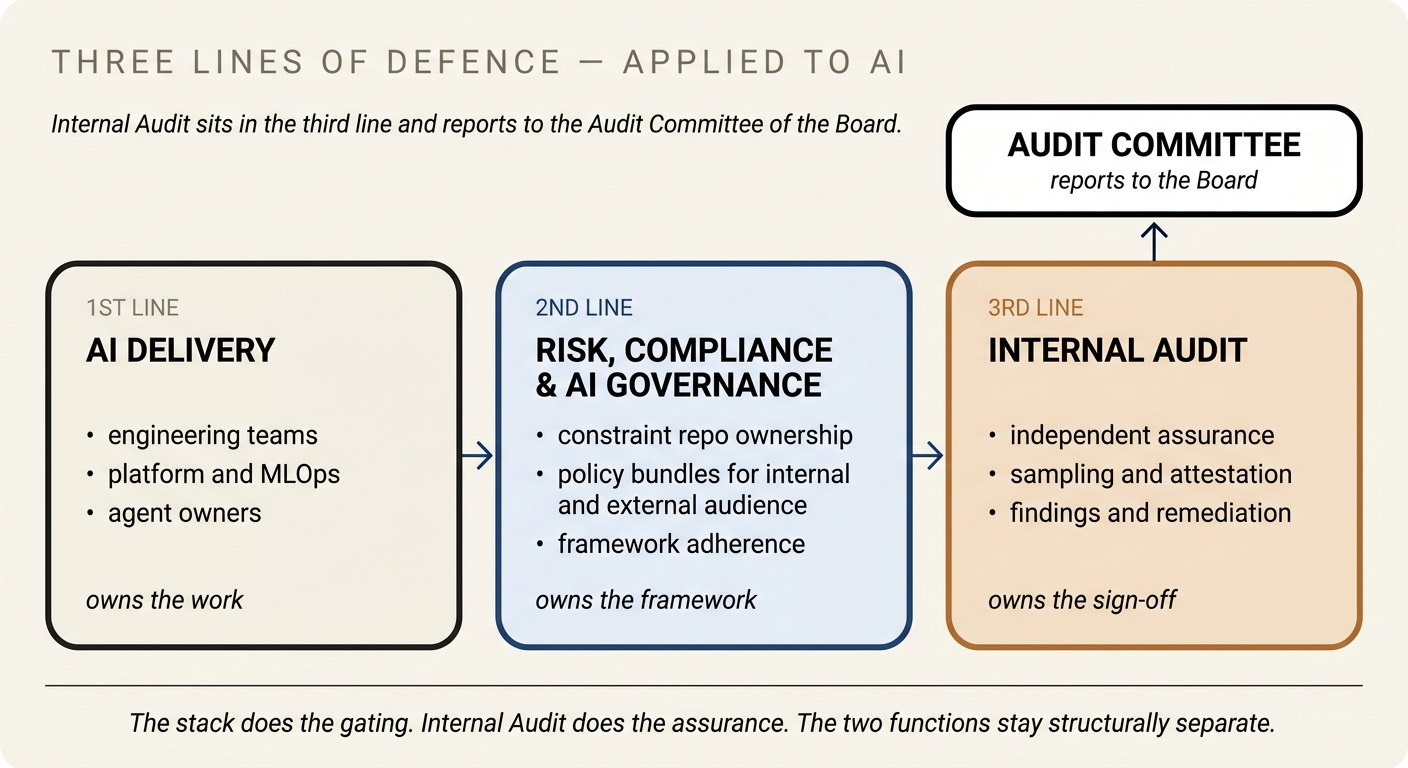
Three properties matter, and they are already there in a mature Internal Audit function. Reporting line: IA reports to the Audit Committee of the Board, not to the CEO. The committee, not management, sets scope, approves budget, and receives findings. Standing to demand evidence: IA has a long-established right of access to logs, systems, and documentation — the same right that lets them audit the financial close, the identity stack, or the change-management process applies to AI. Defined product: IA's output is a written finding with an agreed remediation path and a follow-up audit. That is the shape of the artefact the AI trust authority needs to produce.
What Internal Audit is not is a real-time gatekeeper. They cannot stop a deployment at 3am. They cannot evaluate every Trust Token as it is minted. The architectural implication is important: IA becomes the body that sets the policy bundles, reviews the evidence the stack emits, and attests to the board. The actual gating is still done by architecture — by the gateway for Class A, by the contract and the vendor's own controls for Class B, by the data-plane and managed-browser policy for Class C. The stack does the gating. IA does the assurance.
That separation is a feature, not a compromise. The failure mode of putting an audit function in the control path is that the function stops being an audit function — it becomes another ops team with a different tie. Keeping IA structurally off the control path is what lets them refuse to sign when something looks wrong without being captured by the SLA they were protecting.
Not every organisation has an Internal Audit function strong enough or technically deep enough to carry this. The alternative design — covered in detail in Section 9 — routes the trust-authority role through an external attestor, typically the consulting arm of a Big Four firm issuing SOC-style attestation reports against an AI control framework. It trades speed and continuity for structural independence and external credibility. Pick it when outside assurance is what you need; otherwise the in-house version is faster, cheaper, and more integrated with the rest of the three-lines model.
3 — The Assured Trust Stack
The five-layer model from the Solo Trust Stack still holds. What changes in the Assured version is that L2 (validation), L3 (execution), and L4 (Trust Token) all have to handle three very different kinds of origin cleanly. L0 and L1 barely change — governance and policy are written in the abstract and bind the same way regardless of where the agent runs.
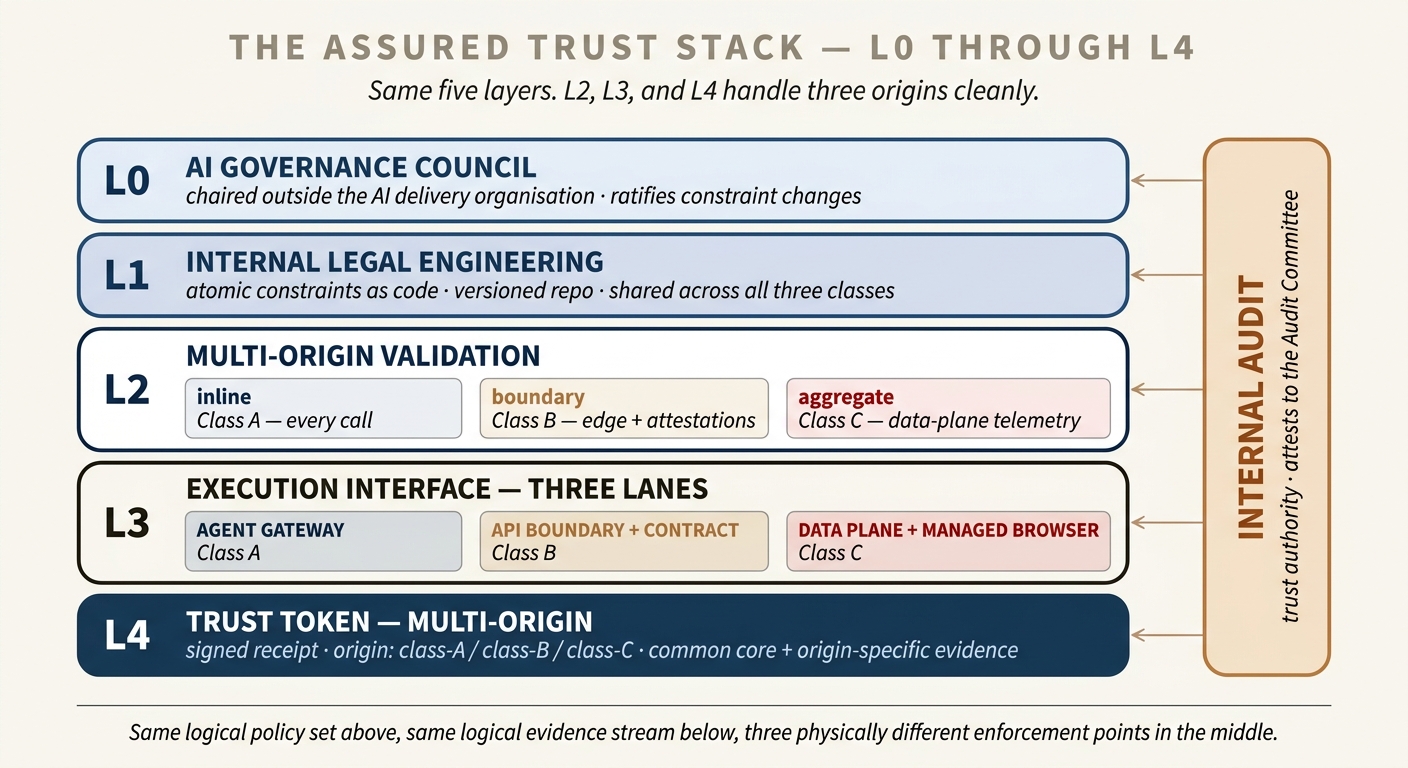
L0 — AI Governance Council. Unchanged from the Solo version. Chaired outside the AI delivery organisation — typically the CRO, the General Counsel, or a Chief Risk officer. Sets policy, ratifies high-stakes constraint changes, meets on a published cadence with a written charter. The council is where business, legal, and risk agree on what the constraints should say before the engineers encode them.
L1 — Internal Legal Engineering. Atomic constraints written in a small DSL, stored in a versioned repository, code-reviewed and released through the same pipeline as production code. The constraint repo is deliberately policy-not-class: rules are written about decisions and audiences, not about whether the agent is Class A, B, or C. The same “never commit a customer to a refund without Ops co-sign” rule applies whether it is being enforced at a wire-level gateway, at a Salesforce Agentforce flow boundary, or on a managed browser via DLP inspection.
L2 — Multi-origin Validation. This is where the Assured Trust Stack diverges most from Solo. Validation has to consume three kinds of evidence: inline policy evaluation on every tool call for Class A, boundary evaluation at the vendor API edge plus periodic consumption of vendor attestation feeds for Class B, and aggregate evaluation of data-plane and endpoint telemetry for Class C. The three look different on the wire but are reconciled against the same constraint repo and produce receipts with the same Trust Token format. The validation engine is policy-in, evidence-out; the shape of the evidence changes by origin.
L3 — Execution Interface. Three lanes, one substrate. The agent gateway from Solo runs Class A unchanged. A vendor-boundary component — effectively a thin policy proxy that sits on the API edge between your systems and the vendor's agent — runs Class B. A data-plane-and-endpoint layer — Purview, your DLP, your managed-browser policy, your CASB — runs Class C. All three emit into the same audit substrate and mint Trust Tokens in the same format.
L4 — Trust Token, multi-origin. Every receipt carries an origin field: class-A, class-B, or class-C. The rest of the record — policy version, inputs hashed, model or vendor fingerprint, co-signers, validity window — is structured the same way. The origin field is what lets Internal Audit reason honestly about what the token evidences: a class-A token is a record of an enforced decision; a class-B token is a record of a bounded-and-attested decision; a class-C token is a record of a use boundary, not a content control.
Same stack, different integration pattern per class. You do not build three trust architectures. You build one, and you accept that the “execution interface” layer is three physically different enforcement points with one logical policy set above them and one logical evidence stream below.
4 — What the gateway can actually intercept
The most important sentence in this document is the one that describes what the gateway can do in each class, because it is the sentence the rest of the architecture is built around. The Solo Trust Stack's gateway was a wire-level control that refused, modified, or co-signed every agent action before it left the building. That model runs unchanged for Class A. It runs partially for Class B. It does not run at all for Class C — and a design that pretends it does is a design that will get caught in its first incident review.
The honest per-class control surface is worth naming explicitly, because a lot of vendor marketing in 2026 is still implying the opposite.
Class A: full-gateway intercept
You wrote the agent or you deployed it on infrastructure you control. Every tool call passes through a central gateway that holds credentials no agent holds directly. The gateway can refuse, modify (redact fields, downgrade scope, substitute parameters), require co-signing, and revoke a session in flight. Trust Tokens are minted on every approved call with the full receipt — policy version, inputs hashed, model fingerprint, co-signers, validity window. This is the configuration the Solo Trust Stack described, and it is fully reachable today for anything you build.
The non-negotiable is the deprivation: agents cannot reach tools or data directly. Short-lived capability tokens are minted by the gateway, scoped to a tool and a task, with a clock. Egress firewall and no ambient credentials in the agent runtime make this physical rather than aspirational. Every team that tries to skip this step arrives at the same lesson three months later.
Class B: boundary-and-contract intercept
Your Salesforce Agentforce agent is reasoning inside Salesforce. You did not write it, you cannot trace every reasoning step, and there is no meaningful sense in which your gateway sits between the agent and the model. What you can do sits in three places. At the API boundary between the vendor's agent and any of your systems — every webhook, every callback, every tool invocation the vendor's agent makes against your services — you enforce policy in a proxy you operate. The vendor's agent can only reach what your proxy allows. In the vendor's configuration — scopes, roles, data-access policies, prompt guardrails the vendor exposes — you configure the tightest admissible setting, version it in your own repo, and treat drift between the vendor's console and your repo as an incident. In the contract and the attestations — the MSA, the DPA, the SOC 2 Type II, any AI-specific attestation the vendor offers — you transfer risk you cannot physically enforce to the vendor's own controls and to the remedies you negotiated.
What you cannot do is pre-evaluate the agent's reasoning before it happens. You learn about a misstep when it crosses your boundary or when the vendor's own controls report it. Trust Tokens for Class B therefore carry a reference to the vendor's attestation and a record of the boundary decision, not a record of the agent's internal deliberation.
Class C: use-boundary only
Your employee opens claude.ai or copilot.microsoft.com, pastes a draft, and reads the reply. There is no integration point where you can enforce a constraint on the model's reasoning. The things that are available to you are all on your side of the screen. Data-plane labels and DLP decide what content the employee is able to paste in. Microsoft Purview or your equivalent classifies documents and blocks the copy, or the DLP on the outbound side catches the exfiltration and alerts. Managed-browser policy decides which agents are even reachable: Edge for Business, Chrome Enterprise, or an equivalent restricts the allow-list of provider URLs, disables extensions that bypass controls, and enforces that the session is signed in as the enterprise identity. Endpoint telemetry captures that the interaction happened, at what scale, and with what class of content — even if you never see the prompts themselves. Approved-provider contracts — an enterprise tenancy with Anthropic, Microsoft, or OpenAI under a commercial agreement with no-training clauses, SOC 2, and a meaningful audit right — are the legal analogue of the data-plane controls.
Trust Tokens for Class C are qualitatively different. They record a use boundary, not a content control: that an employee invoked an approved provider from a managed endpoint, with what class of data the provider could have seen based on labels and DLP posture, under which approved-provider agreement. A class-C Trust Token is the receipt for “we enforced the boundary we actually have,” not for “we inspected the decision.”
A single gateway cannot cover all three. An organisation that spends its AI-control budget building one super-gateway and plugs Class B and C in by adapter is building a logging proxy for B and C dressed up as control. The Assured Trust Stack accepts three physically different enforcement points — wire-level gateway for A, API-boundary-plus-contract for B, data-plane-plus-endpoint for C — and federates them under one policy set and one audit substrate. The architecture earns its name by making this three-to-one mapping explicit, not by hiding it.
5 — The Class A / B / C playbook
With the control surface for each class named, the operational playbook follows. The pattern is the same across all three — every agent registers, the stack enforces what it can, a Trust Token is minted, and Internal Audit reviews the evidence — but the mechanics are different enough to be worth spelling out.
Class A — the agent you build
Registration is architectural. Every Class A agent is identified by a cryptographic service identity issued by the platform team; it has a manifest that declares its purpose, its tool set, its audience class, and its constraint subset; and it can only reach the network through the gateway. At deploy time the manifest is compared against the constraint repo and the deploy is blocked if there is a mismatch. At runtime, every tool call is evaluated synchronously — allow, deny, modify, or escalate — against the current policy set. Budgets (spend, call count, records touched, wall-clock) are enforced in the gateway. Circuit breakers at the agent-class level trip on error rate, anomaly score, or drift.
The Trust Token has the full receipt. Inputs hashed, policy version, model fingerprint, co-signers where co-signing applied, validity window, budget consumption, tool-call chain. If Internal Audit needs to reconstruct what happened on 14 March at 11:04, they can. This is the configuration the Solo Trust Stack described and it remains the richest evidence any of the three classes produces.
Class B — the agent your vendor ships
Registration is commercial before it is technical. The first artefact is a decision, ratified by the AI Governance Council, that this vendor's agent is approved for a named use case with a named audience. That decision is backed by vendor evidence: the SOC 2 Type II, the ISO 42001 or equivalent AI management-system attestation, the DPA, any AI-specific questionnaires (the NIST AI RMF profile the vendor can produce, the Anthropic/OpenAI/Microsoft-style model card for the embedded model), and the contractual audit rights. The stack records this as a vendor profile: an identity for the vendor's agent inside your registry, the attestations it relies on, their expiry dates, and the policy bundle it inherits from its audience class.
Technical enforcement then happens at two points. At the API boundary, every call between the vendor's agent and any of your systems flows through a lightweight proxy that applies the same constraint repo to the requests and responses it can see — scope, redaction, two-key on commitments, outbound-message policy. At the vendor side, the configuration (allowed scopes, allowed tools, allowed data sources, prompt guardrails) is version-controlled in your repo and reconciled against the vendor's console on a schedule; drift is a change-management event, not a “someone tweaked it.”
The Trust Token carries a reference to the vendor profile, the boundary decision (what the proxy did to the call), and a pointer to the relevant attestation. When Internal Audit asks “how do you know the vendor's agent did not do X,” the answer is a composite: the boundary evidence says the vendor could not have X'd across your boundary, and the vendor's attestation says their own controls prevent X internally. The composite is meaningfully weaker than a Class A Trust Token; it is also meaningfully stronger than no receipt and a vendor logo in a slide deck.
Class C — the agent your people open in a browser
Registration is provider-level, not agent-level. The AI Governance Council approves a short list of providers that your organisation is willing to use at all: for this worked example, assume Microsoft Copilot (under an M365 E5 enterprise agreement with no-training clauses), Claude (under Anthropic's enterprise tier), and ChatGPT (under an OpenAI enterprise or ChatGPT Enterprise agreement). Every other provider is blocked at the managed-browser allow-list and on the corporate network. The approval is the registration; the evidence is the contract.
Enforcement then has three layers. The corpus — what any of those providers could in principle read — is shaped by sensitivity labelling (Purview or equivalent), by conditional-access policies that deny highly-classified content from being pasted into an AI-provider domain at all, and by DLP rules on outbound clipboard, file upload, and typed content. The browser — Edge for Business or Chrome Enterprise with a managed profile — enforces the allow-list, blocks disallowed extensions, and requires the session to be signed in with the enterprise identity, not a personal one. The endpoint — through your EDR and managed-device posture — captures that the interaction occurred, with what label class, at what volume.
The Class C Trust Token is a boundary receipt. It says: on this date, this employee, at this endpoint, with this enterprise identity, interacted with this approved provider, with data of no higher sensitivity than Confidential based on the labels present in the browser at the time, under the provider contract effective 3 February 2026. It does not say what the agent reasoned, and it should not pretend to. Internal Audit is able, from this, to answer “is our Class C usage within the envelope we approved,” which is the question that matters. They cannot answer “did Claude phrase this paragraph correctly on 14 March,” and neither can anyone else.
Class A: full receipt, wire-level intercept. Class B: boundary receipt plus vendor attestation, contract as defence-in-depth. Class C: use-boundary receipt, data-plane and provider-contract as the real enforcement. Same Trust Token format, same constraint repo, same Internal Audit review cadence. The strength of the evidence varies by origin, and the audit workpaper has to treat it that way.
6 — The audience axis still applies
The audience axis from the Solo Trust Stack carries forward without modification. Whether an agent's output ultimately reaches an internal employee or an external customer still determines which policy bundle applies — the internal bundle (scope check by role, PII redaction, draft co-sign on high-stakes artefacts, internal Trust Token) or the external bundle (outbound-message policy, two-key on commitments, per-conversation validity window, external Trust Token). What the three-class world adds is a second axis running orthogonally. Class is about how you can enforce the bundle. Audience is about what the bundle contains.
Together they form a 3×2 map, and every AI deployment in the organisation sits in exactly one cell. The cell names the integration pattern (from the class) and the policy bundle (from the audience). Read correctly, it is the single chart the AI Governance Council and Internal Audit return to most often: it shows what is approved, what bundle applies, and what evidence the organisation is entitled to expect.
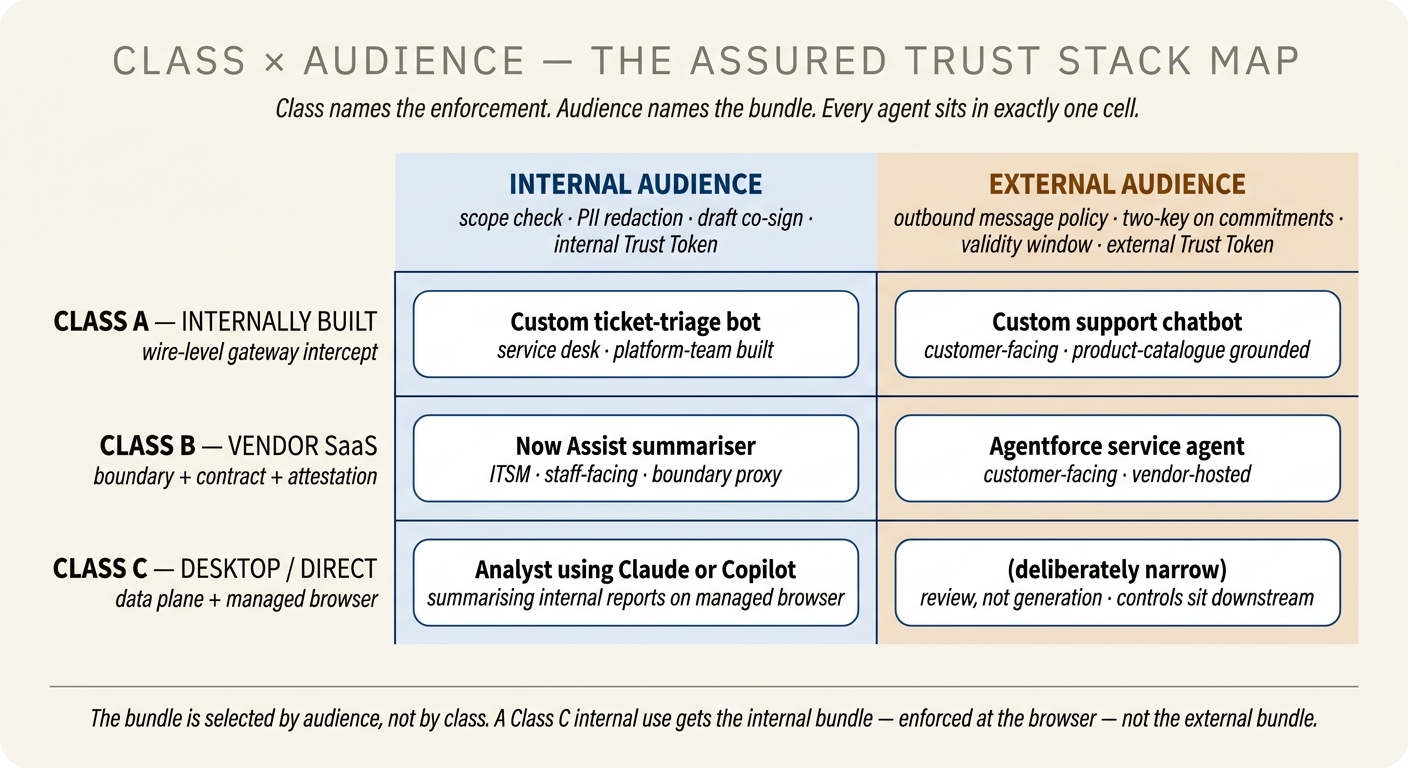
Worked through briefly. A Class A internal agent — say, a custom ticket-triage bot the platform team wrote for the service desk — runs under full wire-level intercept with the internal bundle: scope check by role, PII redaction on inputs, draft co-sign on any HR-adjacent artefact. A Class A external agent — the customer-support chatbot your engineers built against your product catalogue — runs under the same intercept with the external bundle: outbound-message policy, two-key on refund commitments, validity window per conversation. A Class B internal agent — the Now Assist summariser embedded in your ITSM — runs under boundary-and-contract with the internal bundle: scope enforced in the ServiceNow policy graph, redaction applied at the boundary proxy, co-sign captured in the workflow. A Class B external agent — Agentforce's service-cloud agent on your public channels — runs under boundary-and-contract with the external bundle: outbound policy at the Salesforce edge, two-key on commitments configured in the flow, validity window enforced by the vendor. A Class C internal usage — an analyst pasting an internal report into Claude for a summary — runs under use-boundary with the internal bundle: the internal Trust Token captures the boundary, Purview labels decide whether the paste was even permitted. A Class C external usage is deliberately narrow and usually policy-forbidden — a marketer using a desktop agent to draft customer-facing copy gets the external bundle applied at review, not at generation, and the controls sit in the downstream publishing workflow.
The value of naming the matrix explicitly is that most governance debates simplify once it exists. “Is this approved?” becomes “which cell is it in?” “Why did we not catch that?” becomes “what does our evidence for that cell look like?” “Should we adopt this vendor?” becomes “does its cell's evidence meet our threshold?”
The bundle is selected by audience, not by class. A Class C desktop use by an employee drafting an internal memo gets the internal bundle — enforced at the managed-browser layer — not the external bundle, even though the agent's servers live outside your network. The agent's audience is still internal. External bundle applies when the agent's output is going to reach a customer, regardless of where the agent runs.
7 — The Trust Token, with three origins
The Solo Trust Stack's Trust Token was a signed JSON receipt per consequential decision: who asked, against which policy version, with which inputs hashed, with which model fingerprint, with which co-signers, inside which validity window, when. That format survives unchanged. The Assured Trust Stack adds one field — origin — and uses it to keep Internal Audit honest about what the receipt actually evidences.

Origin: class-A. The tool-call chain is attached — every gateway decision in the chain that produced the outcome, each with its own allow/deny/modify/escalate verdict and its own policy-version hash. The gateway identity that minted the token is a cryptographic root the stack owns end-to-end. This is the strongest form of evidence the Assured Trust Stack produces: Internal Audit can, in principle, replay the decision deterministically from the token and the constraint repo snapshot it references.
Origin: class-B. The boundary decision is attached — what the proxy did to the request and the response, under which policy version, with which co-signers. A reference to the vendor's current attestation is attached: SOC 2 Type II report ID and period, ISO 42001 certificate ID, AI-specific attestation if one exists, and the contract clause the attestation is being relied on for. The token is a composite of “what we enforced at the boundary” plus “what the vendor attests they enforced inside.” Internal Audit cannot replay the decision — the reasoning happened in the vendor's system — but they can evaluate whether the boundary was correct and whether the attestation being relied on was current and in scope.
Origin: class-C. The use boundary is attached — the enterprise identity that invoked the provider, the managed-browser policy active at the time, the sensitivity-label posture of the session, the DLP posture of the endpoint, and the approved-provider contract reference effective on the date of the interaction. The content of the interaction is not attached and should not be; the provider's enterprise agreement is where that question is answered contractually. The token is evidence that the interaction happened within the envelope the organisation approved. Internal Audit can answer “was the envelope correct on this date?” and “did this interaction stay inside it?” They cannot answer “what did the provider do with what it saw?” without reaching for the vendor relationship.
A common token format — with an origin field and origin-specific evidence sections — lets Internal Audit run a single audit query across all three classes and reason about the result knowing the evidence is heterogeneous by design. Split formats produce split audits, and split audits are the shape that gets a trust authority captured by whoever produces the richest evidence. One format, one query, three honestly-labelled strengths of evidence.
From mint to attestation — the token's lifecycle
The anatomy figure shows what is inside a Trust Token. It does not show where the token lives between being minted on the wire and being read by someone who has to trust it. The picture below traces that journey end-to-end and, importantly, names the place where the evidence sits before any of it has been published.
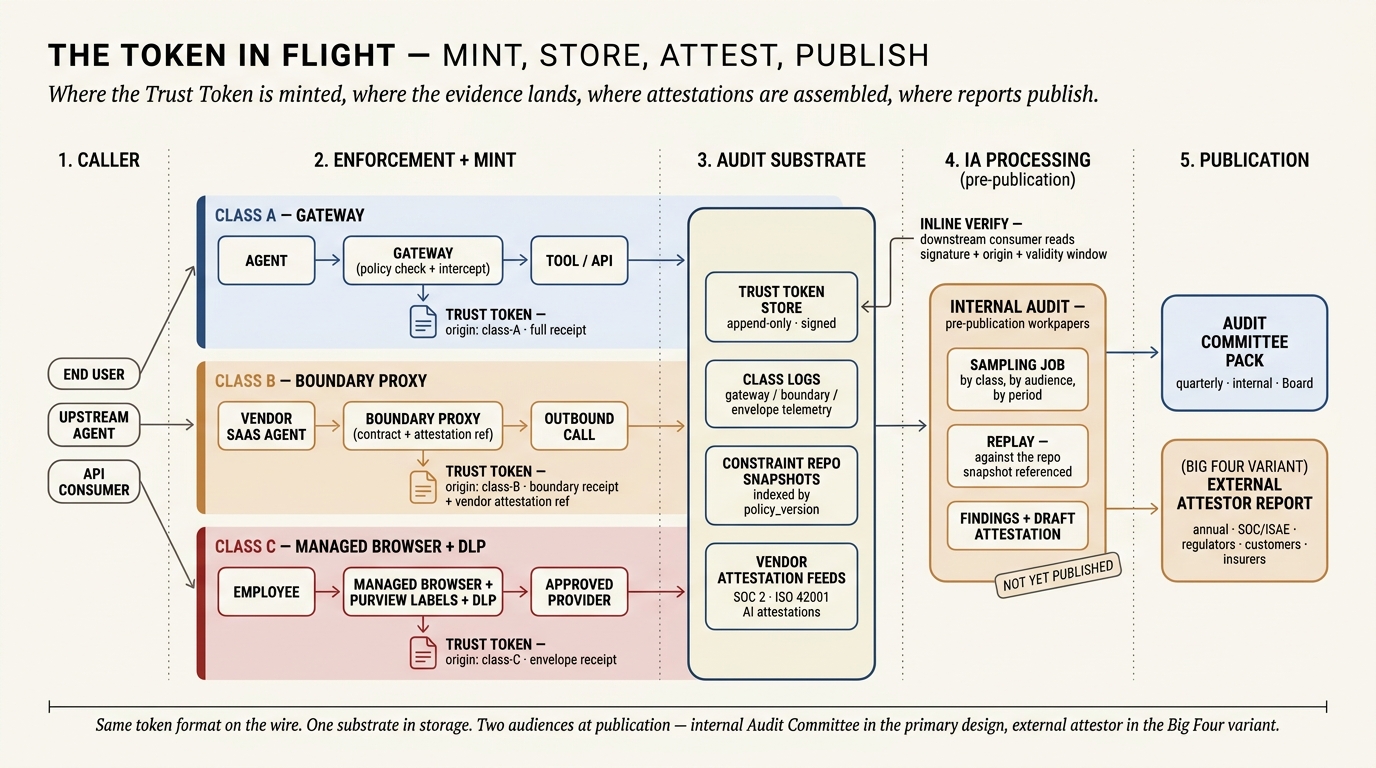
Mint. The three lanes in Zone 2 are the only places in the architecture where a Trust Token comes into existence. For Class A the gateway signs it as part of the tool-call decision, with the full chain attached. For Class B the boundary proxy signs it as the request leaves or the response returns, with the vendor's current attestation referenced by identifier. For Class C the managed-browser layer signs it at session boundaries, with the envelope posture — label state, DLP rule set, approved-provider contract reference — attached. The three enforcement points are physically different pieces of infrastructure, but the token format they emit is the same, and the origin field on each is what lets Internal Audit read them under one query later.
Storage — the audit substrate. All three classes converge on a single append-only store. The Trust Token store itself holds every signed receipt indexed by token_id, policy_version, actor, and timestamp. Alongside it sit the class-specific logs — gateway telemetry, boundary-proxy transcripts, managed-browser and DLP events — that the tokens reference but do not copy. The constraint repo snapshots are kept at each policy_version so that a token can be replayed against the exact policy state in force at the moment it was minted. The vendor attestation feeds land in the same substrate on their own cadence, so that when a Class B token references attestation cert_2026-02, Internal Audit can resolve that reference without leaving the system. This store is the single source of truth for everything the Trust Stack claims about itself. It is write-once by design, its retention is set by the regulatory framework the organisation operates under, and it is the read surface Internal Audit is entitled to access directly.
Inline verification. Not every use of a Trust Token waits for Internal Audit. A downstream internal consumer — a second agent that will act on the first agent's output, a human reviewer in a co-sign workflow, a partner API that requires a signed provenance receipt — verifies the token on the wire. They check the signature against the gateway's public key, read the origin field to decide how much weight to place on the receipt, and check the validity window has not closed. That is the inline-verify arrow in the figure, and it is what makes the Trust Token useful in operational flows rather than only in audit.
IA processing — where report data sits before it is published. The sampling job in Zone 4 reads from the audit substrate on a cadence. It draws tokens by class, by audience, by period; replays them against the repo snapshots referenced; looks for exceptions; investigates the ones that matter; and accumulates its findings into draft attestations. Everything in this zone is deliberately not yet published. Draft attestations are reviewed inside the IA function, marked up, revised, signed off by the head of Internal Audit, and then — and only then — moved into the publication stage. The distinction matters for two reasons. First, regulators and attestors both care about when a finding became a finding, and the workpaper system provides that record. Second, the confidentiality of draft findings is itself a control: an organisation whose in-flight audit observations leak to the first line before the audit closes has lost the independence it is trying to demonstrate. The workpaper system is the quiet room. The Audit Committee is the first audience that reads the finished output.
Publication. The top box in Zone 5 is the quarterly Audit Committee pack: coverage numbers, findings, attestation status, a forward risk view. The committee accepts, asks, or escalates. The Board hears the committee's summary. In the Big Four variant the same evidence package is also transmitted to the external attestor, who performs their own sampling against the substrate during their audit period and issues a separate report — a SOC report, an ISAE report, an ISO 42001 certification — readable by regulators, customers, and cyber-insurers without them needing to understand the internal organisation chart. Two audiences at publication, two signatures, one underlying substrate of evidence.
A well-designed Trust Stack is one where the same token, minted by different infrastructure, lands in one substrate, is sampled by one trust authority, is held in workpapers before anyone outside that authority sees it, and is published in exactly two forms: an internal committee pack and an external attestor report. The architecture earns the right to be called assured only when every one of those stages has a named owner, a retention policy, and a scheduled cadence. Everything before publication is workpaper. Everything at publication carries a signature that says “this has been examined.”
Sequence detail — a request, end to end, in each class
The lifecycle figure shows the architecture at rest: where the token is minted, where it lands, who reads it when. The three figures below zoom in one level further and trace a single request through each class of agent, from the caller's first input to the point at which a Trust Token exists and the response is back in the caller's hands. They are the clearest picture of what the stack does per interaction — and, importantly, of what it does not do per interaction.
- Solid arrows are real-time steps — always in the path, executed on every request.
- Diamond gates are conditional — they fire only when a rule triggers (a co-sign threshold, a redaction match, a DLP rule).
- Person icons mark human steps — where a person, not a machine, is the actor on that line.
- Dashed arrows with a clock are async — writes to the audit substrate, vendor attestation drops, reverse-path telemetry. They happen outside the real-time flow, on a queue or a cadence, and are not a per-request tax on the agent.
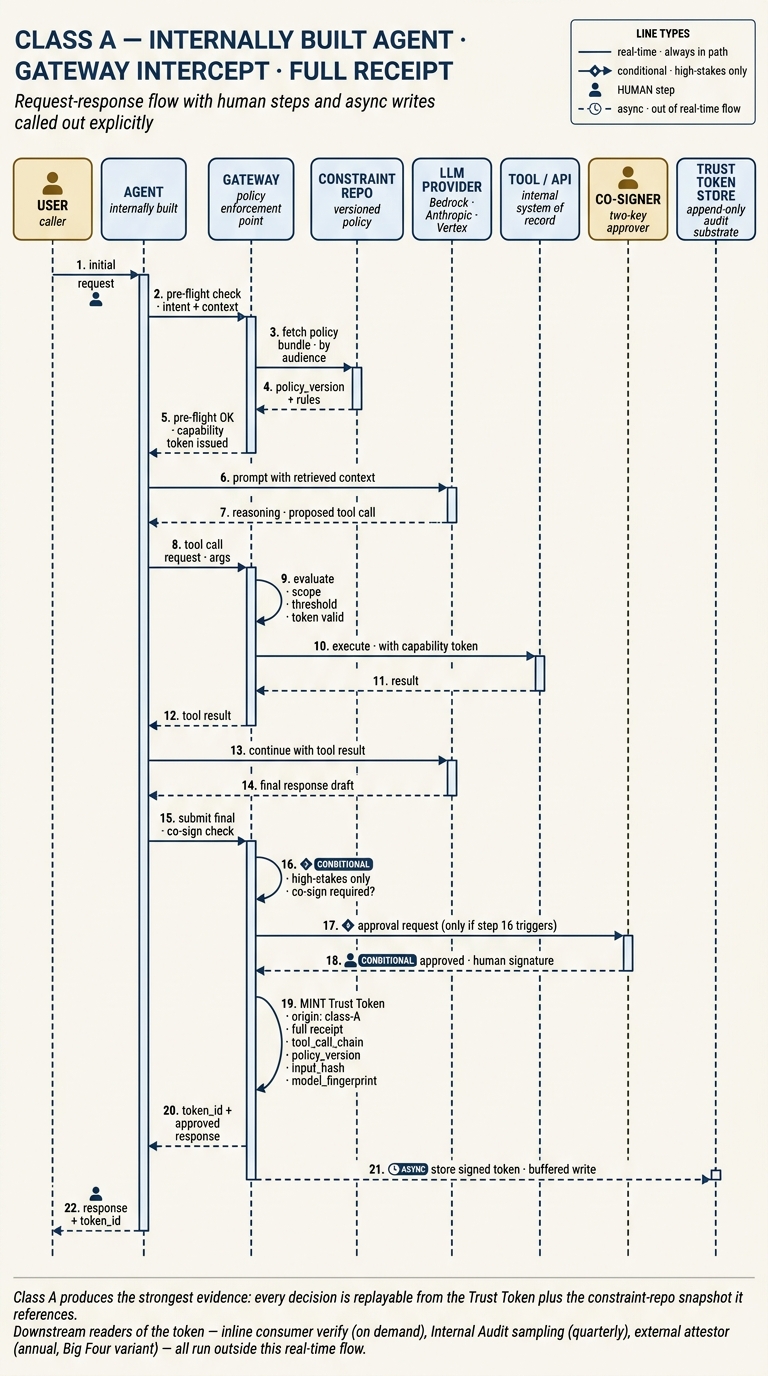
Class A — gateway intercept, full receipt
In Class A the gateway sits in the real-time path between the agent and every tool it calls. The solid spine of the diagram — pre-flight check, policy fetch, capability token, LLM reasoning, tool execution, final draft — runs on every request. The conditional branch is the high-stakes co-sign: step 16 is a diamond gate that only triggers when the action's blast radius or financial threshold crosses the policy line, and steps 17–18 bring a human co-signer into the flow to approve a specific minted action. The Trust Token is signed at step 19 with the full tool-call chain, the input hash, the policy_version, and the model fingerprint attached. The write to the Trust Token Store at step 21 is deliberately async: the signed receipt is buffered to the append-only substrate on a queue rather than blocking the response to the user. This is the strongest evidence the stack produces, and it is the flow an external attestor can ask Internal Audit to replay deterministically.
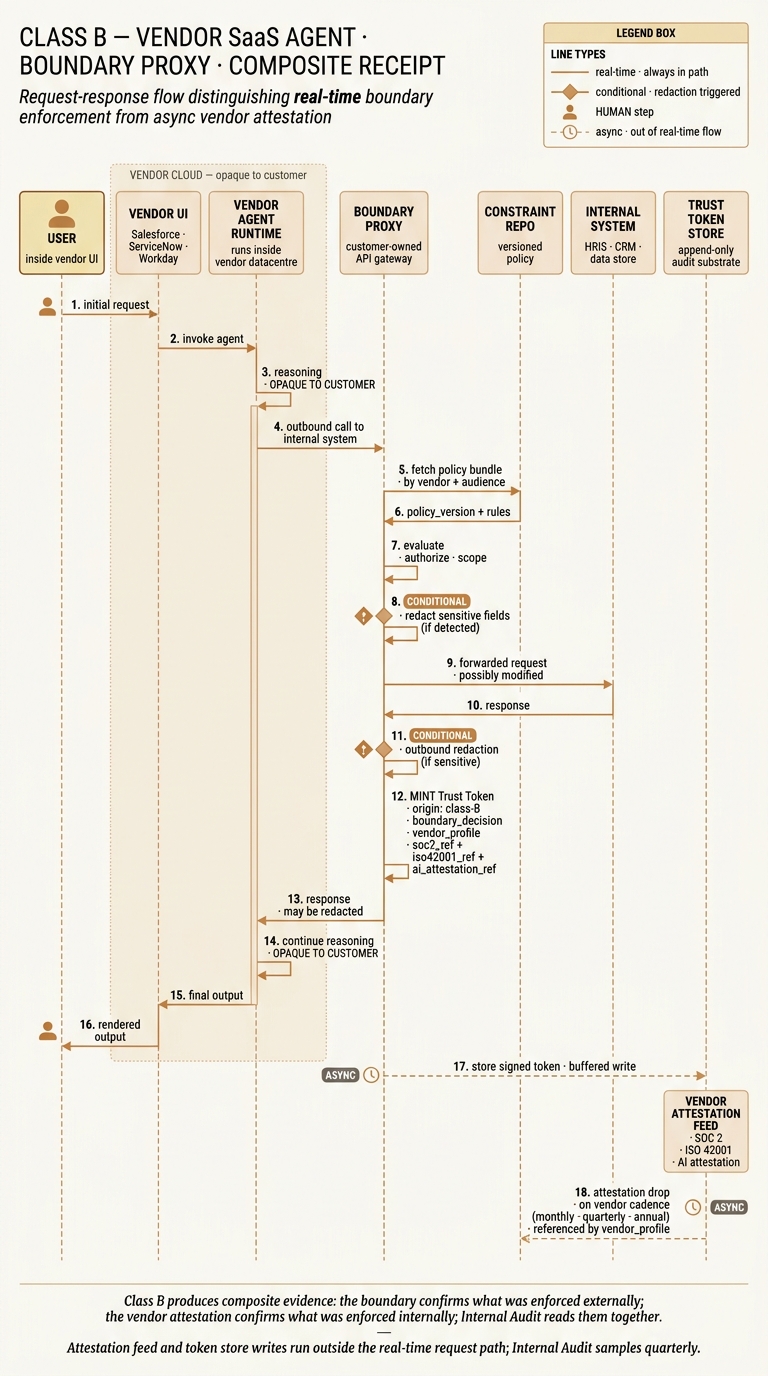
Class B — boundary proxy, composite receipt
In Class B the vendor runs the agent inside their cloud, and the stack can only see and shape the traffic crossing the boundary. The real-time path is short: the vendor's agent reasons internally (opaque to the customer, shown as a shaded band), makes an outbound call, the customer-owned boundary proxy fetches the applicable policy, evaluates the request, and forwards it — possibly modified. Two diamond gates mark the conditional redaction steps: step 8 redacts sensitive fields in the forwarded request if the proxy detects them; step 11 performs outbound redaction on the response if the vendor returned something the envelope does not allow to leave. The Trust Token minted at step 12 is a composite: a boundary-enforcement decision plus references to the vendor's current SOC 2, ISO 42001, and AI attestations. The dashed lines at the bottom are important: step 17 writes the signed token to the substrate on a buffered cadence, and step 18 is the vendor attestation drop — monthly, quarterly or annually depending on the certificate — which is indexed by vendor_profile so Internal Audit can resolve the reference later. Neither of those asynchronous steps blocks the user-facing response, and neither is generated per-request.
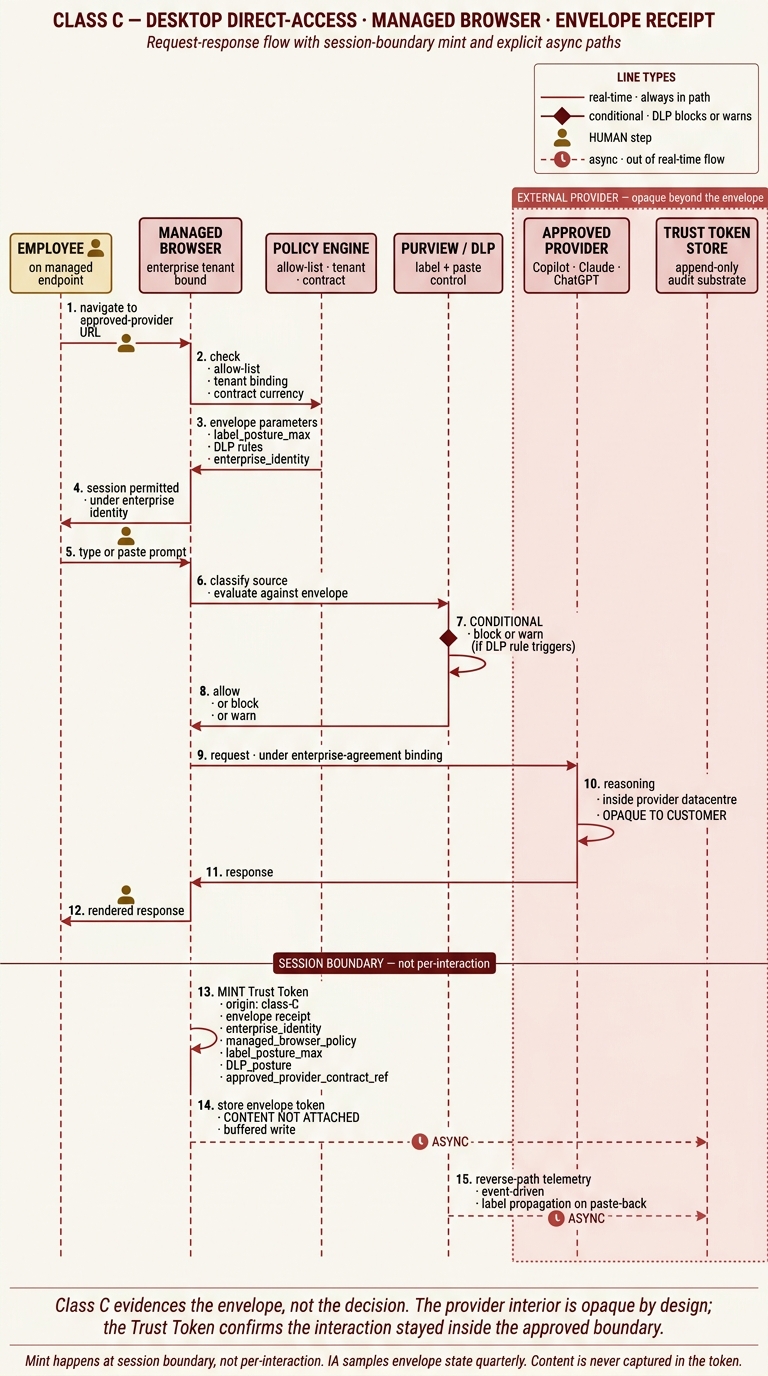
Class C — desktop direct-access, envelope receipt
In Class C the employee interacts with an approved provider — Copilot, Claude, ChatGPT — through a managed browser on a managed endpoint. The real-time path runs from navigating to the provider URL, through the managed-browser's tenant and allow-list checks, Purview label and DLP classification, and the interaction itself, which happens inside the provider's infrastructure and is opaque to the customer by design. The conditional diamond gate at step 7 is the DLP decision: the session allows, blocks, or warns based on label posture and rule state. The critical visual device in this diagram is the session-boundary separator between steps 12 and 13. Everything above it runs per interaction. The Trust Token mint at step 13 and the envelope-token write at step 14 run at the session boundary, not per pane or per keystroke. Content is never attached; only the envelope parameters are. The reverse-path telemetry at step 15 is both async and event-driven — label propagation on paste-back fires only when a user pastes content from the provider into something else, and the event lands in the audit substrate on its own queue. This is why the Class C evidence burden is lighter and more diffuse than Class A or B: the stack is attesting to the envelope, not to every interaction inside it.
Reading the three diagrams side by side makes the shape of the stack honest. The real-time spine of every class is small — a few enforcement and mint steps in the critical path. The substantive assurance work — sampling, replay, attestation reconciliation, committee reporting — is async, scheduled, and cadenced. That is the property that lets the Assured Trust Stack scale: what lives in the user's request is only enforcement and receipt. What lives in Internal Audit's quarter and in the external attestor's year is the rest.
8 — Internal Audit as the trust authority
Most regulated enterprises already have an Internal Audit function, it already reports to the Audit Committee, it already has rights of access that everyone in the organisation is used to respecting, and it already produces the shape of artefact this job requires: an independent written finding with a remediation path and a follow-up audit. Putting IA in the trust-authority role is mostly a matter of scoping the mandate, equipping them technically, and setting the cadence. It is the cheapest place to start, the most structurally integrated place to land, and the place whose authority is most plausibly durable across the next ten years.
What the role does, concretely, sits in four activities.
Ratifying the policy bundles
The constraint repo contains the policies. The AI Governance Council drafts changes. Internal Audit reviews them against the regulatory framework the organisation has committed to, against prior findings, and against the attestation obligations the organisation has made to external stakeholders. An IA sign-off is required on any change to the internal or external bundle. This is not a veto — the council can override with the right reasons on the record — but the override itself is an audit event, and it accumulates.
Sampling and attesting to the evidence
IA does not read every Trust Token. They sample. For Class A, sampling is statistical — a draw of tokens per quarter, replayed against the constraint repo snapshot at the time, with exceptions investigated. For Class B, sampling is a mix of boundary tokens (replayed the same way) and vendor attestations (verified in scope, in period, and unqualified). For Class C, sampling is at the envelope level — label posture, browser policy state, DLP rule coverage, contract currency — on a quarterly cadence, with a sentinel look at endpoint telemetry for out-of-envelope behaviour. The output is an attestation to the Audit Committee, written in the same register as every other audit attestation the committee receives.
Running the trust-authority incident path
When something goes wrong — a Class A agent minted a refund it should not have, a Class B vendor's agent leaked context it should not have seen, a Class C user exfiltrated content the labels should have prevented — Internal Audit is the body that reconstructs what happened from the receipts, names the control failure, and tracks the remediation. The first-line team may well run the operational incident. IA runs the assurance incident, and the findings it produces are what the Audit Committee reads. This is the mechanism that keeps the stack honest over time: the cost of a finding is proportional to the severity, the remediation is tracked, and the follow-up audit closes the loop.
Reporting to the Audit Committee
On a committee cadence — usually quarterly — IA delivers a report that covers coverage (what percentage of approved AI is registered, what percentage of usage is in-envelope), findings (open, remediated, aged), attestations (which are current, which are expiring, which have been qualified), and a forward risk view. The committee accepts, asks, or escalates. The Board hears the committee's summary. This is the only sentence in the document that says how this architecture actually gets defended in front of a regulator, and it is the most load-bearing: a regulator asking “who at your organisation is accountable for AI assurance?” gets a direct answer with a reporting line that an outside lawyer can verify.
What IA needs in order to do this credibly
The honest prerequisites are small in number but real. IA needs a dedicated AI-assurance capability — at least one senior auditor whose full-time mandate is this, with technical depth sufficient to read a constraint rule, replay a Trust Token against a repo snapshot, and challenge a vendor attestation. IA needs read access to the audit substrate — the Trust Token store, the gateway logs, the Purview and DLP posture, the managed-browser policy version history — not via a ticket to the platform team but directly, the same way they access the GL. IA needs a committee-level scope letter that explicitly covers AI, written by the Audit Committee chair and refreshed annually. And IA needs budget insulation — their staffing for this role should not be negotiable with the CIO whose systems they audit. If any of these four is missing, the authority is on paper.
Internal Audit shares a CEO, an HR system, and an equity grant with the rest of the organisation. Their independence is structural but not absolute. They do not hold the professional standards body's sanction that a registered external auditor holds. And in organisations where the IA function is small, under-funded, or technically thin, the role cannot credibly be carried no matter how good the scope letter is. Where any of that is true, Section 9's alternative is not a second-best — it is the right design.
9 — The Big Four alternative
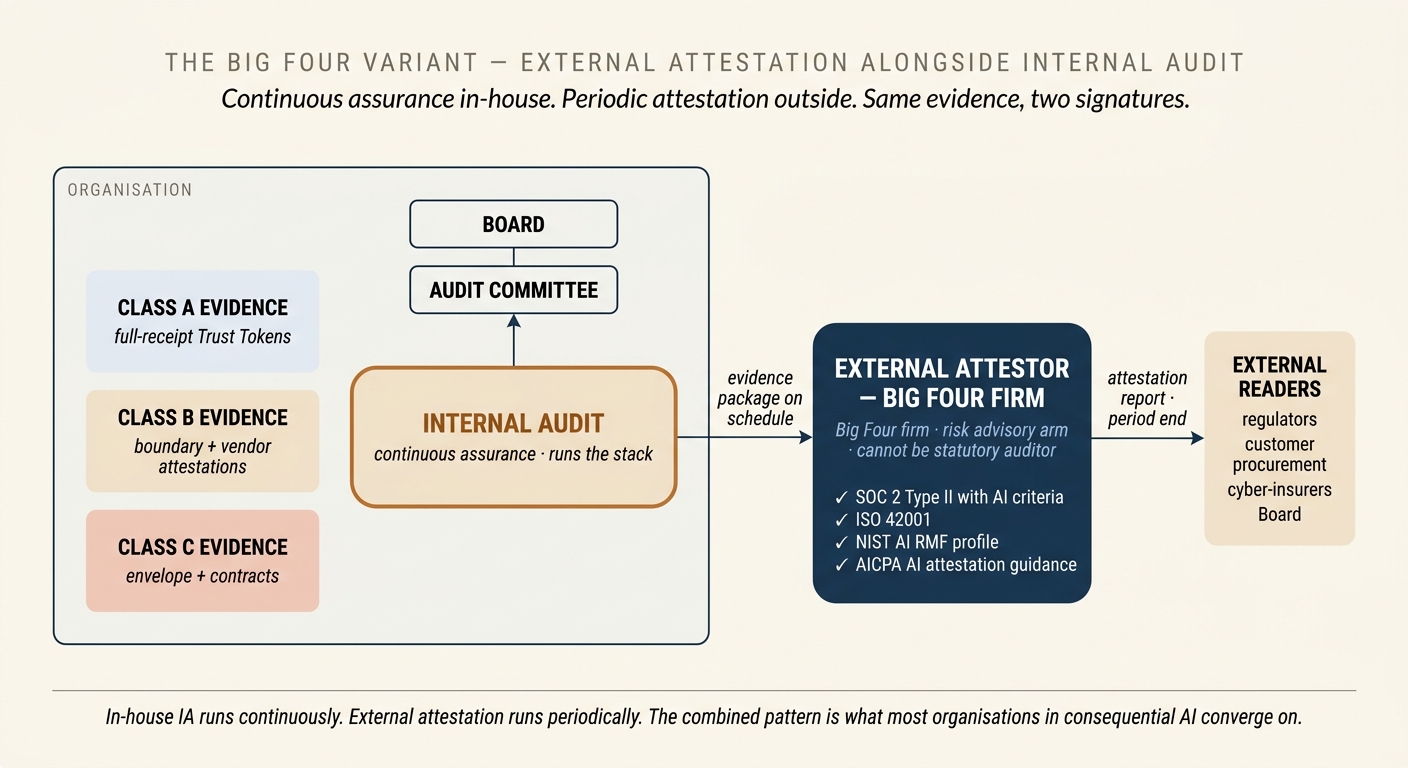
The alternative design routes the trust-authority role through an external attestor — in practice, the risk-advisory or consulting arm of a Big Four firm (Deloitte, EY, KPMG, PwC) or one of the independent attestation firms that have emerged around SOC and ISO. The attestor does not replace Internal Audit — IA still exists and still reports to the Audit Committee — but the artefact that carries external credibility is an attestation report signed by the external firm, against a named AI control framework, for a defined period.
The right framings to reach for in 2026 are the ones the profession has already converged on: SOC 2 Type II extended with AI-specific criteria, ISO 42001 as the AI management system standard, NIST AI RMF as the control library, and the emerging AICPA AI attestation guidance. The firm's report says, for the period under examination, that the organisation's AI controls as described were suitably designed and operating effectively, with any exceptions noted. Internal readers use the report the same way they use the SOC 2 for any other outsourced process. External readers — regulators, customers, cyber-insurers, investors — use it as third-party evidence that the control environment is real.
The independence constraint nobody advertises
The firm doing the AI attestation cannot be the firm auditing your financial statements. Auditor independence rules in every major jurisdiction prohibit the same firm from providing significant non-audit services to an audit client, and AI control attestation of this scope will not pass that test at any material organisation. If your statutory auditor is Deloitte, your AI attestor is one of the other three. This is not a minor procurement detail — it shapes which firm you are buying from, which partners you are in a room with, and how the two engagements reference each other in your disclosures.
What external attestation buys that in-house cannot
Three things, precisely. Structural independence that survives a change of CEO: the firm's partners cannot be fired by your management, their professional standards body sanctions them if they sign a report they should not, and their ongoing liability to external stakeholders is real. Cross-industry benchmarking: the firm sees fifty organisations running similar stacks in the same quarter, and your report is produced by people who know which of your controls are above or below the median. Portable credibility: the report is the same artefact that a regulator, a customer-procurement team, or a cyber-insurer will accept from other organisations, so its value in the outside world is calibrated and known. None of these are replicable by Internal Audit alone, no matter how well-staffed.
What it costs, and what it trades away
The engagement is not cheap — expect a materially larger line item than an ISO or SOC engagement you have run before, because the control universe is novel and the evidence is heterogeneous. More importantly, the attestor operates on a periodic cadence — interim and year-end procedures — so the real-time responsiveness that an in-house IA function provides is lost. When something goes wrong on a Tuesday, it is still IA who reconstructs it; the external attestor learns about it at the next interim, in scope if material. The firm is also a vendor: you are buying their independence as much as their expertise, and you pay for their structural insulation in their hourly rate and in the rigidity of their procedures.
When to pick it over the in-house design
Three indications. External assurance is load-bearing for your commercial model — you sell into regulated buyers, you operate under a licence that expects it, or your customer RFPs routinely ask for AI attestation. Your Internal Audit function cannot carry the technical load — it is too small, too stretched, or too operationally embedded for the independence it would need. A credible external signal materially affects your cost of capital or your cost of insurance — cyber insurers are increasingly pricing AI risk into renewals, and a credible attestation measurably moves the premium. Absent these, Internal Audit is the better bet.
Organisations rarely choose one design against the other. The pattern that has settled out in the market through 2026 is Internal Audit as the continuous trust authority with Big Four attestation on a defined cadence — typically annual, with interim procedures quarterly. IA does the running, the firm does the signing. The combined cost is higher than either alone, and the assurance is materially stronger than either alone. For any organisation where AI is in the consequential decision path, this is the design to aim at.
10 — A 90-day rollout
The sequencing that has worked in practice is counter-intuitive to anyone used to starting with the biggest exposure. The biggest exposure is Class C — employees already using desktop agents at scale — but Class C is also where the controls are the most diffuse and the quickest wins are in data-plane hygiene you are probably already investing in. Start with Class A, where the architecture is tightest and the wins are most provable, so that the rest of the organisation can see what “inside the envelope” looks like. Then pick up Class B, because the contracts and attestations take real calendar time and you want them in flight by day thirty. Class C work runs in parallel from day one — the managed-browser rollout is not waiting on anything else — but the operational acceptance of the Class C Trust Token's narrower claim takes longer than anything else, and that is the work of weeks four through thirteen.
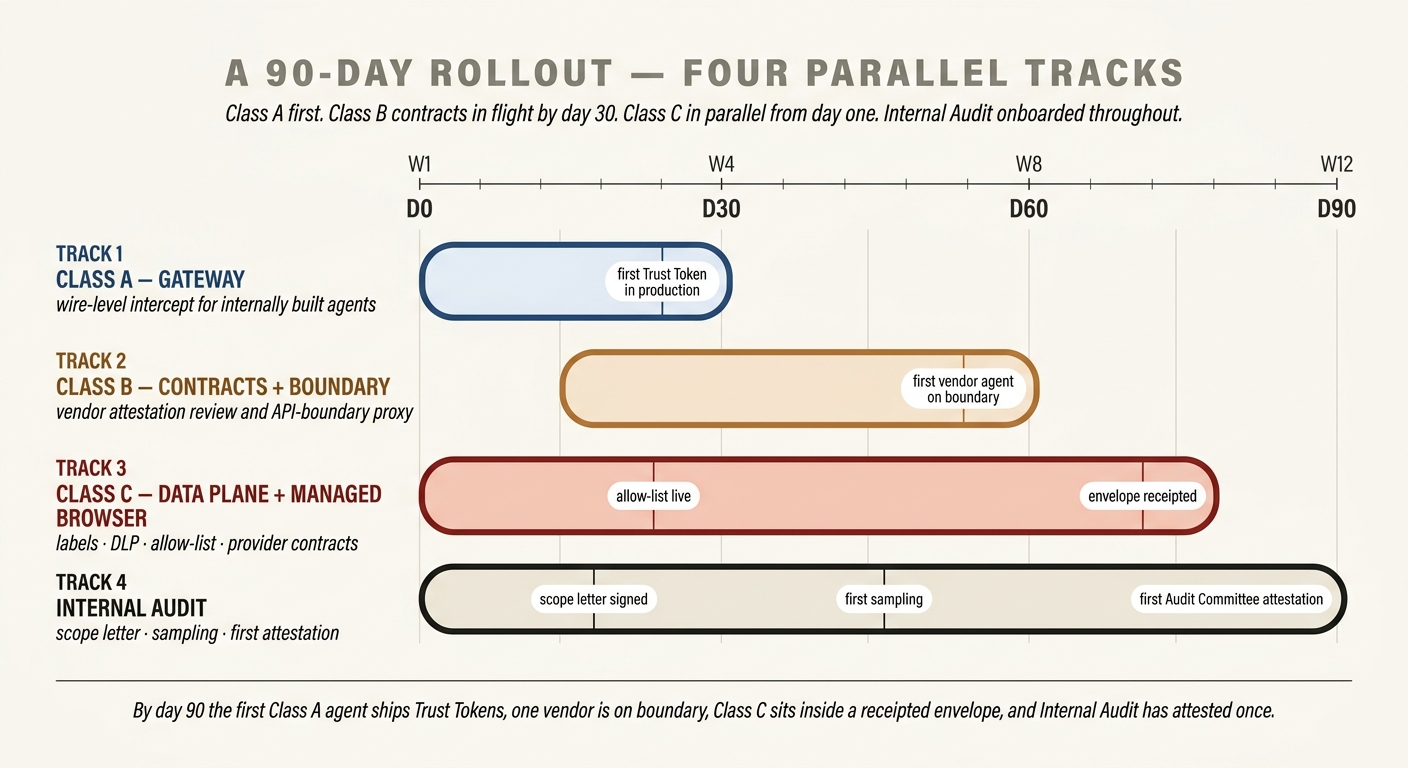
Days 1–30 — Class A gateway and Internal Audit scope letter
Stand up the gateway with one reference agent in production. Connect the constraint repo, the audit substrate, the Trust Token mint, and the policy engine. Onboard one well-understood agent — a ticket triage, a knowledge search, a claim summariser — and run it under full intercept end to end. In parallel, the Audit Committee approves a scope letter that explicitly covers AI assurance; IA staffs the dedicated role; the AI Governance Council publishes its charter. By day thirty, one Class A agent is shipping Trust Tokens and IA has the standing to audit them.
Days 15–60 — Class B contracts and boundary proxy
Identify the three or four vendor SaaS agents that matter most — usually a CRM agent, an ITSM agent, and an HRIS agent — and start the contract-and-attestation work. Request current SOC 2 Type II, ISO 42001 or equivalent, and any AI-specific attestation. Negotiate audit rights and data-access terms if they are not already in the MSA. In parallel, the platform team stands up the boundary proxy and puts the first vendor agent through it. By day sixty, one Class B agent is shipping boundary-and-attestation Trust Tokens and the remaining vendor relationships are in a known state.
Days 1–75 — Class C data plane and managed browser
Turn on managed-browser policy with an approved-provider allow-list limited to those with enterprise agreements and no-training clauses. Roll out Purview labels on the content classes that matter most — customer PII, regulated data, source code, M&A material — and wire DLP rules for paste-and-upload on those classes to the approved-provider domains. Deploy endpoint telemetry that captures class-level interaction data without capturing prompt content. By day seventy-five, Class C is inside an envelope and the envelope is receipted.
Days 30–90 — Internal Audit first sampling and first attestation
IA samples the first quarter's Trust Tokens: a draw of Class A tokens replayed against the repo, a boundary-plus-attestation review for Class B, an envelope review for Class C. Findings are opened, remediations agreed, follow-up dates set. On day ninety the first attestation report goes to the Audit Committee. Subsequent cadences follow the committee's schedule.
Can one Class A agent be refused a tool call in production? Can one Class B agent's request be modified at the boundary? Can one Class C provider be added to or removed from the allow-list by policy, not by a shadow IT ticket? Can Internal Audit produce a written finding that names a remediation owner and a date? If all four are true by day ninety, the rollout is real and the architecture is earning its name. If any of them is still hypothetical, the rollout has not started — regardless of what the status deck says.
11 — Feasibility, and what it buys
The question this piece opened with is whether the Trust Stack pattern survives a world where most AI is not the AI you built. The answer is yes, but with three strengths of evidence the architecture has to be honest about. It is worth saying the summary plainly.
Class A is fully feasible today. The gateway, the constraint repo, the Trust Token mint, the co-sign patterns, the validity windows — all of it runs now, in production, against real agents, inside real audit substrates. The engineering is no longer novel; it is a well-understood discipline that your platform team can stand up in a quarter. Internal Audit can attest to it with the same rigour they apply to the financial close, and an external Big Four attestor can sign a SOC-style report against it.
Class B is feasible with vendor cooperation. The boundary proxy is engineering you own. The contracts and attestations depend on what the vendor has already produced and what they will agree to negotiate. In 2026 the best vendors have substantive SOC 2 + ISO 42001 attestations with AI-specific criteria and will grant audit rights; the middle of the market has something adjacent; the bottom still ships a logo and a hope. Your approved list is a function of what you can actually evidence, and the Assured Trust Stack makes that function mechanical. The weaker Trust Token for Class B is honest, not defective: you are relying on a composite of your boundary and the vendor's internal controls, and the token says exactly that.
Class C is partially feasible — and that is the right word. You control what data reaches approved providers, which providers are reachable at all, and under what contract. You do not control what the providers do with what they see, and no architecture will change that. The Class C Trust Token is a boundary receipt, not a decision receipt. Pretending otherwise is the thing that gets a stack's credibility destroyed on its first incident. The correct framing — the Class C problem is a data-governance problem that masquerades as an AI problem — tells you where the investment has to go: Purview and DLP posture, managed-browser discipline, enterprise-grade provider contracts, and endpoint telemetry. All of these pay off whether or not an AI agent is involved, which is a useful property.
What the in-house and the Big Four variants each buy
The in-house design buys you speed, integration, and continuity. Internal Audit is in the building, they know the business, and they can produce findings on a Tuesday. The cost is that the independence is structural but not absolute, and the credibility of the report outside the organisation depends on how strong your IA function already is.
The Big Four variant buys you structural independence, cross-industry benchmarking, and portable credibility. The report is the same shape of artefact a regulator, a customer, or an insurer will read without needing to know your organisation. The cost is periodic cadence, higher expense, and a firm whose product is their independence rather than their familiarity with your systems.
The combined pattern — in-house IA running continuously, Big Four attesting on a cadence — buys you both, and is the design most organisations with AI in consequential decisions will converge on. The architecture is the same either way. What differs is whose signature carries the credibility to which audience.
The Assured Trust Stack is a single trust architecture federated across three physically different enforcement points, producing three honestly-labelled strengths of evidence, read and signed by a body whose independence from the delivery organisation is structural. Same stack. Three classes. One authority.